KMP算法
- 导读
- 一、`KMP`算法
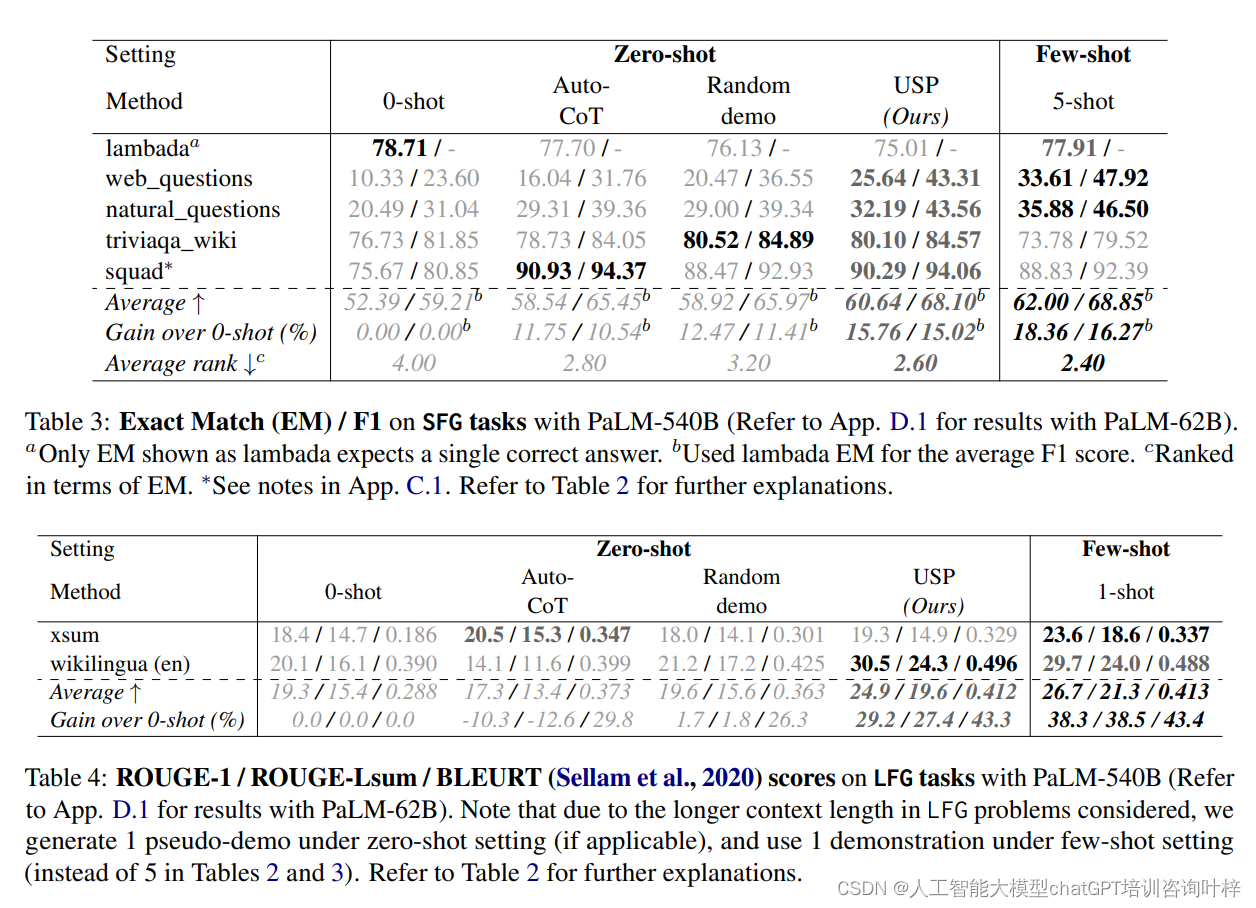
- 1.1 重要术语
- 1.2 部分匹配值
- 1.3 部分匹配值的作用
- 二、`KMP`算法原理
- 2.1 从指针的角度理解`KMP`算法
- 2.2 从匹配的角度理解`KMP`算法
- 2.3 小结
- 三、`KMP`算法的实现
- 3.1 next数组
- 3.2 next数组的计算
- 3.2.1 通过PM值计算next数组
- 3.2.2 通过移位模拟计算next数组
- 3.2.3 小结
- 3.3 C语言实现`KMP`算法
- 3.3.1 串类型的选择
- 3.3.2 函数三要素
- 3.3.3 函数主体
- 3.4 代码测试
- 四、`KMP`算法的缺陷
- 结语

导读
大家好,很高兴又和大家加面啦!!!
在上一篇内容中,我们详细介绍了朴素模式匹配算法及其实现。朴素模式匹配算法简单的理解就是将主串中以每一个位序上的元素为开头的子串与模式串进行匹配,直到匹配成功,或者匹配完主串中的所有可能的子串。
这种模式匹配方式有一个很明显的缺陷——因为需要不断的进行指针的回溯,导致消耗了大量的时间,而且还会多次执行一些不必要的匹配,如下图所示:

当我们在以主串首元素a开头的子串与模式串进行匹配后,我们可以很清楚的直到主串的第二个元素肯定是与模式串中的首元素不匹配的,这时如果能够直接跳过这个匹配的过程直接来到主串中的第三个元素与模式串的首元素进行匹配,如下所示:

像这样我们就可以节省一次匹配的过程。同理,如果在其它的例子中,我们都能够跳过这些无用的匹配过程,算法的效率就可以大幅度的提升。
能够在模式匹配过程中自动过滤掉无用匹配过程的算法,就是我们今天要介绍的串这个章节中唯一的重难点——KMP算法。
看到KMP算法,想必有些朋友已经开始脑壳疼了,什么是KMP算法?它的原理是什么?如何实现KMP算法?等等诸如此类的问题已经占满了各位的大脑。为了帮助大家减轻痛苦,接下来我们就直接进入今天的正题吧!!!
一、KMP算法
KMP算法全称是Knuth-Morris-Pratt Algorithm(克努特—莫里斯—普拉特算法)实际上就是优化后的模式匹配算法。这个算法是由D.E.Knuth、J.H.Morris、V.R.Pratt这三位大佬提出。

Donald·E·Knuth大佬帅照附上

James H. Morris大佬帅照附上

Vaughan·R·Pratt大佬帅照附上
1.1 重要术语
在介绍KMP算法之前,我们先要对子串的结构有一个初步的认识,首先给大家介绍串中的几个重要概念:
- 前缀:前缀是指除了最后一个字符以外,字符串所有的头部子串;
- 后缀:后缀是指除了第一个字符以外,字符串所有的尾部子串;
- 部分匹配值:部分匹配值是指字符串的前缀和后缀的最长相等前后缀长度。
为了更好的理解这些概念,下面我们以一个具体的实例来说明,如字符串"abcabc":
- 前缀指的是除了最后一个字符
'c'外,字符串所有的头部子串,如""、"a"、"ab"、"abc"、"abca"、"abcab"; - 后缀指的是除了第一个字符’a’外,字符串所有的尾部子串,如
""、"c"、"bc"、"abc"、"cabc"、"bcabc"; - 部分匹配值指的是字符串中的前缀和后缀的最长相等前后缀长度:
- 子串
"a"的前缀为空串""(∅),后缀为空串""(∅),其中"" == "",最长相等前后缀长度为0; - 子串
"ab"的前缀为空串""和"a",后缀为空串""和"b",其中"" == "",最长相等前后缀长度为0; - 子串
"abc"的前缀为空串""和"a"和"ab",后缀为空串""和"c"和"bc",其中"" == "",最长相等前后缀长度为0; - 子串
"abca"的前缀为空串""和"a"和"ab"和"abc",后缀为空串""和"a"和"ca"和"bca",其中"" == ""、"a" == "a",最长相等前后缀长度为1; - 子串
"abcab"的前缀为空串""和"a"和"ab"和"abc"和"abca",后缀为空串""和"b"和"ab"和"cab"和"bcab",其中"" == ""、"a" == "a"、"ab" == "ab",最长相等前后缀长度为2; - 子串
"abcabc"的前缀为""、"a"、"ab"、"abc"、"abca"、"abcab",后缀为""、"c"、"bc"、"abc"、"cabc"、"bcabc",其中"" == ""、"a" == "a"、"ab" == "ab"、"abc" == "abc",最长相等前后缀长度为3;
- 子串
因此,字符串"abcabc"的部分匹配值为000123。
1.2 部分匹配值
现在大家对前缀和后缀应该是理解了,但是这个部分匹配值可能还不是很理解,为什么我们找部分匹配值是从左往右找呢?这些值又有什么含义呢?下面我们来通过图片进一步理解:

在上图中,我们对主串T和模式串K进行模式匹配时,不难发现,我们匹配的方向是从左往右进行匹配,实际上就是从左往右将主串和模式串的子串进行匹配,因此我们所求得的部分匹配值也是从左往右进行求解。
现在可能有朋友还是会有疑问,为什么在求部分匹配值时是将模式串的子串前缀后缀进行比较呢?
对于这个问题,我们可以理解为,这是为了检测模式串中重复字符的位置,如果我们将模式串的部分匹配值(Partial Match,PM)以表格的形式表示,那就可以得到下表:

从表中我们可以看到,所谓的PM值,实际上就是重复的子串中各元素上一次在模式串中出现的位置。这里我们要思考一下为什么是上一次?

在上图中,我们计算出了模式串"abcabcabc"的各子串所对应的PM值。不难发现,从第4个元素开始,每个子串所对应的PM值刚好就是对应的元素前一次的位序。
导致这种情况的原因正是因为我们在计算PM值时采用的是比较该字符串中的后缀与前缀。当一个子串的前缀后缀相同时,那就说明后缀中的元素与前缀中同位序的元素相同。在前缀子串中,子串的长度、元素个数与元素的位序满足:
子串的长度
=
元素的个数
=
子串最后一个元素的位序
子串的长度=元素的个数=子串最后一个元素的位序
子串的长度=元素的个数=子串最后一个元素的位序
因此,我们求解的PM值,实际上就是在找与前缀字符串中元素有重复的子串,当找到该子串时,我们会将前缀字符串重复的子串最大长度给记录下来,而这最大长度刚好就对应了前缀字符长中重复子串最后一个字符所对应的位序。
这里又是重复子串,又是重复子串最大长度,又是重复子串最后一个字符所对应的位序,可能有朋友都已经有点晕乎乎的了。没关系,下面我们通过图片来进一步的理解:

从图中我们可以看到,对于子串"abcabc"而言,它的前缀子串和后缀子串中有重复的子串为"abc",而该子串在前缀子串中的最大长度为3,子串的最后一个字符为'c',该字符在前缀子串中所在的位序为3。
同理,继续往后匹配的话,子串的长度增加,在上图的例子中,重复的子串长度也会增加,重复子串中最后一个字符会发生改变,而该字符所对应的位序正好就是前缀子串中重复部分最后一个字符所对应的位序。
因此,我们可以得到结论:PM值是该子串中的最后一个字符前一次出现的位序。
1.3 部分匹配值的作用
现在大家应该对部分匹配值有一定的理解了,接下来我们就需要探讨一下这个PM值的作用了。接下来我们还是通过实例来进行理解,如下图所示:

在这个例子中,模式串的前五个字符都完成了匹配,在第六个字符发生了失配。此时我们就需要对模式串重新开始进行匹配,从逻辑上来看的话就好比将模式串向后进行了移动。
在朴素模式匹配算法中,此时我们需要将模式串向后移动一位,使得第二次匹配从主串的第二个字符也就是'b'开始与模式串的首字符'a'进行匹配。

显然'b' != 'a',这时的匹配过程就是一个无效的匹配过程,这就是朴素匹配模式存在的缺陷,会进行很多的无用匹配,
如果我们要避免这些无用匹配过程的发生,我们就需要移动一个更加准确的次数来进行下一次匹配,这个移动次数的获取就需要用到我们之前求出的PM值。
在获取了模式串的PM值后,我们可以借助下面的公式来推算出我们需要向后移动的位数:
移动位数
=
已成功匹配的字符数
−
匹配成功的子串对应的部分匹配值
移动位数=已成功匹配的字符数-匹配成功的子串对应的部分匹配值
移动位数=已成功匹配的字符数−匹配成功的子串对应的部分匹配值
在第一次匹配的过程中我们已经完成了5个字符的匹配,而子串"abcab"对应的部分匹配值为2,此时根据公式我们可以得到我们需要移动的位数为
5
−
2
=
3
5-2=3
5−2=3 位。
为了更直观的看到PM值与移动位数的关系,我们可以列出下面的关系表:

在这个表中可能有朋友会对第一个字符的匹配成功的PM值有些许疑问,为什么是-1而不是0?
- 这里我们简单的理解一下,如果当第一个字符发生失配时,我们只能将模式串往后移动一位,让模式串的首字符与主串的下一个字符进行匹配,因此我们通过-1来表示首字符失配时匹配成功的PM值。
从上表中我们不难发现,从模式串第4个字符开始失配时移动的位数都是3,刚好跳过了前三个字符的依次匹配,也就是说,根据这个关系表,我们在进行二次匹配时,可以直接将失配的元素与模式串的第三个元素进行匹配:

通过这种方式,我们可以看到,相比于朴素模式匹配算法,此时的模式匹配跳过了2次无用匹配的过程,很好的提高了匹配的效率。
这种借助PM值进行移位来完善模式匹配的算法就是我们要介绍的KMP算法。惊不惊喜,意不意外。我们在不经意间就已经介绍完了KMP算法了。今天的内容到此结束,下一篇再见!!!
哈哈哈,开了个小玩笑。对于KMP算法,我们现在才只简单的进行了了解。接下来我们才要开始继续深挖KMP算法。
二、KMP算法原理
现在我们对KMP算法的了解停留在需要记住PM值来进行移位从而达到快速匹配的效果,它的原理是什么,我相信肯定还有朋友不太了解,下面我们会通过几个角度来理解KMP算法的原理。
2.1 从指针的角度理解KMP算法
在朴素模式匹配中,我们是通过借助3个指针完成的模式匹配,这时会遇到几个问题:
- 主串的指针在失配时需要经常性的回溯
- 已经成功匹配的部分在下一次匹配中会进行无意义的匹配
这两个问题都是导致朴素模式匹配算法时间开销增加的原因,而KMP算法就是用来完善这两个问题来达到减少时间开销的算法,如下所示:

从演示中我们可以看到,在KMP算法中,我们通过PM值获取的移位信息使指针y不再进行回溯,从而减少无用的匹配过程,进而达到降低算法的时间复杂度。
2.2 从匹配的角度理解KMP算法
通过指针来理解的话,我们看到的是KMP算法的表象,确实在KMP算法下,指向主串的指针y是不需要进行回溯,只需要对主串完成一次遍历即可完成整个匹配的过程。下面我们就来看一下它为什么可以不用回溯。
对于计算机而言,它在实际进行匹配的过程中是无法做到一次性读取整个主串的内容的,因此它只能从头对主串依次进行扫描,所以,只有当我们访问主串的元素时,计算机才能知道主串中当前元素是什么。因此实际的匹配过程如下所示:

在整个匹配的过程中,只会出现两种匹配结果——匹配成功和匹配失败:
- 当匹配成功时,此时计算机会继续往后扫描,直到匹配结束或者匹配失败
- 当匹配失败时,此时已经匹配过的元素是计算机已知的,这时我们就可以根据模式串的元素排列规律来进行匹配
这里我们需要重点关注的就是匹配失败时的处理,如下所示:

在第一次失败时,对于计算机而言,此时主串中的元素只访问了出现失配的子串"abcabb",对于失配元素后续的字符是未知的,而我们已知的是该字符串的最长前缀字符串"abcab"肯定是与模式串相匹配的,因此我们不难得到以下信息:
- 模式串的首字符
'a'肯定不可能与主串中的第二个字符'b'和第三个字符'c'相匹配,那这两个匹配对象我们就可以不需要再进行考虑了; - 主串中的第四个元素
'a'和第五个元素'b'肯定和模式串的前两个元素完成匹配,也就是说,这两个元素的匹配我们也是不需要考虑的; - 我们真正需要考虑的就是模式串中的第三个元素与此时失配的主串元素是否匹配。
因此指向主串该元素的指针不需要进行任何回溯,而对于模式串而言,我们只需要根据PM值得到的移动位数将指向模式串的指针进行回溯即可。
现在大家就能很清楚的看到,在这个演示的例子中,通过KMP算法在第一次匹配失败后,到下一次进行有意义的匹配时就比朴素模式匹配算法节省了4次匹配的过程——两次肯定不匹配和两次肯定匹配。不难想象,通过KMP算法进行模式匹配时比朴素匹配算法缩减的时间开销是非常可观的。
2.3 小结
通过上述的两个角度,我们不难得到下列结论:
KMP算法在进行匹配的过程中,通过对模式串进行求PM值的预处理来规避无用的匹配过程;- 在模式匹配中无用的匹配过程包括两类——明显不匹配的过程和肯定匹配的过程;
- 模式串移动的位数就是指向模式串的指针回溯的位数;
- 记录主串中当前匹配子串起点的指针移动的位数与模式串移动的位数相等;
现在大家应该对KMP算法有了更加深刻的理解了。
三、KMP算法的实现
在理解了KMP算法原理后,下面我们就可以尝试着实现KMP算法的整个过程了。
3.1 next数组
在整个算法原理中,我们不难发现,KMP算法的实现很依赖于通过PM值计算出的模式串的移动位数,而算法在移动时实际上就是指向模式串的指针指向移动后的元素对应的下标。
如果我们能够获取每个元素在进行失配时需要将指针指向的对应下标个记录下来的话,这样是不是就会更加方便了呢?
根据这个思路,我们在进行模式匹配前,可以手算出模式串中每个字符在失配时所对应的下标,并将这些下标数据依次存放入一个整型数组中,这样就能够帮助我们实现整个KMP算法了。
这种记录下一次匹配时模式串指针指向的元素下标的数组,我们将其称为next数组。
接下来我们就来探讨一下如何计算模式串的next数组;
3.2 next数组的计算
接下来我将会给大家介绍几种next数组的计算方式,各位可以根据自身的情况来选择适合自己的方式。
在这之前,我们先要明确一个前提条件——字符串中的字符的存储形式:
- 在我们熟悉的字符串中,字符的位序与它所对应的数组下标是相差1的;
- 而我们现在接触的串这种数据结构所遇到的串在进行实际存储时,可能会通过舍弃数组下标为0的空间进行串元素的存储,这种情况下字符串中字符的位序与字符所对应的数组下标是相同的;
在后续的实现过程中我们都是以第一种存储形式——字符的位序与其对应的数组下标相差1的存储形式进行介绍。
3.2.1 通过PM值计算next数组
在前面我们介绍了如何通过PM值来获取失配时指针移动的位数,下面我们就通过PM值来进一步获取模式串所对应的next数组。
由前面的介绍可知,对于模式串"abcabc"而言,串中的各个元素在失配时的PM值以及所对应的需要移动的位数如下所示:

通过这个移动位数,我们可以很快的得到下一次匹配时指针指向的新的位序,这里我们将其称为next位序,计算公式为:
n
e
x
t
位序
=
位序
i
−
对应的移动位数
next位序=位序i-对应的移动位数
next位序=位序i−对应的移动位数
在获得每个元素的next位序后,我们只需要将位序-1就能得到元素所对应的next数组的下标:

在这整个过程中我们进行了:计算字符对应的PM值、计算已匹配的字符数、获取前一个字符对应的PM值、计算移动位数、计算next位序、计算next数组。
!!!当然这里需要注意的是,如果在对串的元素进行存放时采用的是位序=数组下标的方式,那我们获得的next数组中的内容是与next位序的内容是一致的。
在这些过程中我们不难发现,实际对我们有用的只有next位序和next数组的内容,也就是说前面的PM值、匹配字符数和移动位数都是不需要的,因此我们现在要探讨的就是,能不能通过PM值求解next数组是对该过程进行简化呢?下面我们来分析一下PM值与next数组之间的关系;
| 元素 | a | b | c | a | b | c | \0 |
|---|---|---|---|---|---|---|---|
| 位序 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| PM值 | 0 | 0 | 0 | 1 | 2 | 3 | ^ |
| 已匹配字符数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| 匹配成功的PM值 | -1 | 0 | 0 | 0 | 1 | 2 | ^ |
| 移动位数 | 1 | 1 | 2 | 3 | 3 | 3 | ^ |
| next位序 | 0 | 1 | 1 | 1 | 2 | 3 | ^ |
| next数组 | -1 | 0 | 0 | 0 | 1 | 2 | ^ |
现在我们将整个求解过程中涉及到的内容都列在了同一个表格里,从表格中我们可以看到,next数组中存放的值与匹配成功的PM值是相等的,那是不是可以说明next数组实际上就是前一个元的PM值呢?下面我们通过公式来验证一下:
- 假设在一个串长为n的模式串K中,第j个字符发生了失配,接下来我们根据步骤对其next数组中对应的下标next[j]进行一步步的求解:
- 字符j的位序为 j j j
- 有 j − 1 j-1 j−1个字符匹配成功,
- 匹配成功的子串对应的PM值为 P M j − 1 PM_{j-1} PMj−1,
- 需要移动 j − 1 − P M j − 1 j-1-PM_{j-1} j−1−PMj−1位,这里我们将其写成 m o v e = ( j − 1 ) − P M j − 1 move = (j-1)-PM_{j-1} move=(j−1)−PMj−1
- 该字符对应的next位序 n e x t [ i ] = i − m o v e = j − m o v e next[i]=i-move=j-move next[i]=i−move=j−move
- 该字符对应的next数组 n e x t [ j ] = n e x t [ i ] − 1 = j − m o v e − 1 next[j]=next[i]-1=j-move-1 next[j]=next[i]−1=j−move−1
接下来我们将next[j]进行化简,步骤如下:
n
e
x
t
[
j
]
=
j
−
m
o
v
e
−
1
next[j]=j-move-1
next[j]=j−move−1
n
e
x
t
[
j
]
=
j
−
(
(
j
−
1
)
−
P
M
j
−
1
)
−
1
next[j]=j-((j-1)-PM_{j-1})-1
next[j]=j−((j−1)−PMj−1)−1
n
e
x
t
[
j
]
=
j
−
j
+
1
+
P
M
j
−
1
−
1
next[j]=j-j+1+PM_{j-1}-1
next[j]=j−j+1+PMj−1−1
n
e
x
t
[
j
]
=
P
M
j
−
1
next[j]=PM_{j-1}
next[j]=PMj−1
可以看到,经过这一系列的换算后,我们发现模式串的next数组所对应的值next[j]实际上就是前一个字符的PM值。现在我们就获取了第一种求next数组的方式——计算前一个字符的PM值。
!!!如果还有朋友对PM值的计算有疑问的话,可以回看上面1.1和1.2的内容。
3.2.2 通过移位模拟计算next数组
下面我们介绍一种简单粗暴的next数组计算方法——移位模拟。
那什么是移位模拟呢?简单的理解就是我们对模式串中的每一个字符都进行假设失配的情况,并在失配后将模式串进行移位操作,找到合适的匹配对象,该对象所对应的数组下标就是我们需要求解的next[j]。
下面我们以模式串"abcabc"为例,模拟从右到左发生失配的情况:
- 当模式串中的第6个字符发生失配时,我们需要将模式串向右进行移位,如下所示:

在第6个字符发生失配时,我们此时能确定的只有主串中的前5个字符肯定是与模式串相匹配的,接下来就是如上图所示的一样,依次将主串往后进行移位。可以看到,整个移位的过程实际上就是进行前后缀匹配的过程,当前后缀匹配成功时,指针z指向的下标就是第六个字符失配时下一次进行匹配的下标。
- 同理,依次求解出其它字符失配时对应的
next[j]。 - 这里需要注意的是首字符发生失配时的处理,如下所示:

由于首字符左边不存在任何字符,因此当首字符发生失配时,我们只需要将模式串向右移动一位即可,这时按照移位的逻辑,我们可以很容易得到首字符失配时对应的数组下标为-1。但是在这种情况下,我们进行下一次匹配时是无法直接进行匹配的,因此我们还需要同时移动三个指针,确保下一次匹配的正常进行。
3.2.3 小结
从上面的介绍不难看出,不管是求PM值还是进行移位模拟,我们在计算next数组时,实际上就是在手动计算匹配成功部分的PM值—— P M j − 1 PM_{j-1} PMj−1,因此我们可以得到以下结论:
- 计算第
j
j
j个元素的next数组所记录的下标
next[j]就是计算匹配成功部分的PM值—— P M j − 1 PM_{j-1} PMj−1; - 通过PM值计算next数组实际上就是通过手算的方式来计算 P M j − 1 PM_{j-1} PMj−1;
- 通过移位模拟计算next数组实际上就是通过图形化模拟的方式来计算 P M j − 1 PM_{j-1} PMj−1;
- PM值的计算之所以是计算前后缀的最长相等长度,这是因为在移位匹配的过程中前后缀的长度是从j-1开始进行递减的;
3.3 C语言实现KMP算法
在之前的原理解析中我们有提到过,KMP算法实际上就是通过求得的next数组来规避哪些明显不匹配和明确匹配的无效匹配过程,从而来达到降低模式匹配的时间开销,因此我们可以大胆尝试直接在朴素模式匹配的算法基础上进行修改来完成KMP算法。
3.3.1 串类型的选择
在今天的介绍中,我们是采用的直接在朴素模式匹配算法的基础上进行修改,从而实现KMP算法,因此,在今天的演示中我们依旧采用定长顺序存储的串类型,如下所示:
//定长顺序存储
#define MAXSIZE 255
typedef struct StackString {
char ch[MAXSIZE];//字符数组
int length;//当前串长
}SString;//数据类型重命名
3.3.2 函数三要素
算法的完成肯定还是以函数封装的形式,因此算法实现的第一步肯定是要确定函数的三要素——函数名、函数参数、函数返回类型。
- 模式匹配实际上就是串的定位操作,只不过此时我们采用的是
KMP算法实现串定位操作,因此函数名我们选择使用Index_KMP来表示该定位操作是通过KMP算法实现; - 函数的参数在朴素模式匹配算法的基础上,我们需要多传入一个next数组,因此在本次实现的
KMP算法中函数参数有3个——主串S、模式串T和next数组; - 因为我们现在只是通过
KMP算法实现串定位操作,并不需要执行其它内容,因此函数返回类型依旧选择int型;
int Index_KMP(SString S, char* T, int* next) {
//函数实现
}
3.3.3 函数主体
在函数的主体部分我们主要修改的是匹配的过程。在KMP算法中,字符串的匹配我们根据匹配情况可以分为两类——匹配成功和匹配失败:
- 匹配成功时,继续往后扫描
- 匹配失败时,根据字符对应的next[j]进行下一次匹配
int x = 0, y = 0, z = 0;//记录下标的指针
for (x, y, z; S.ch[y] && T[z];) {
if (S.ch[y] == T[z]) {
//当匹配成功时,继续往后匹配
y++;
z++;
}
else {
//当匹配失败时
z = next[z];//通过next数组找到下一次匹配的字符下标
x = y - z;//获取子串的起始位置
}
}
这里需要注意的是,匹配失败时,我们对首字符和其他字符的处理是不相同的,因此这里还需要将首字符的情况单独进行处理:
- 当首字符失配时,next[j]=-1,此时我们需要同时移动y指针与z指针;
if (S.ch[y] == T[z]) {
//当匹配成功时,继续往后匹配
y++;
z++;
}
else {
//当匹配失败时
z = next[z];//通过next数组找到下一次匹配的字符下标
if (z == -1) {//单独处理首字符失配时的情况
y++;
z++;
}
x = y - z;//获取子串的起始位置
}
这样就完成了整个匹配过程的主体,但是此时的代码并不是最优的形式,我们需要将其简化一下。有没有朋友想到如何简化代码呢?
下面我就不兜圈子了,简化代码主要从两个方面入手——合并重复代码、去掉无用代码;
- 从代码中我们可以看到,匹配成功时和下标为-1时,此时执行的操作都是
y++与z++,从代码的执行逻辑上来看,即使我们将其合并也并不会对代码有任何影响,因此这是我们修改的第一个点,合并匹配成功与首字符失配时的处理方式:
for (x, y, z; S.ch[y] && T[z];) {
if (z == -1 || S.ch[y] == T[z]) {
//当首字符失配或者匹配成功时,继续往后匹配
y++;
z++;
}
else {
//当匹配失败时
z = next[z];//通过next数组找到下一次匹配的字符下标
x = y - z;//获取子串的起始位置
}
}
这里需要注意的是一定是z == -1这个判断在前,因为当我们先进行匹配的话,当首字符失配时,此时会出现数组越界的情况,所以我们要先判断首字符是否失配;
- 有细心的朋友可能就会注意到,代码中的x指针其实是没必要存在的,因为指向模式串的指针z它表示的就是模式串的长度,因此在完成匹配时,我们只需要通过主串的当前下标-模式串的长度就能得到模式串在主串中的起始下标。所以,我们可以去掉无用的指针x:
for (y, z; S.ch[y] && T[z];) {
if (z == -1 || S.ch[y] == T[z]) {
//当首字符失配或者匹配成功时,继续往后匹配
y++;
z++;
}
else {
//当匹配失败时
z = next[z];//通过next数组找到下一次匹配的字符下标
}
}
现在我们就得到了KMP算法的完整代码:
//代码简化
int Index_KMP(SString S, char* T, int* next) {
//函数实现
if (!T || strlen(T) == 0)
return -1;
int y = 0, z = 0;//记录下标的指针
for (y, z; S.ch[y] && T[z];) {
if (z == -1 || S.ch[y] == T[z]) {
//当首字符失配或者匹配成功时,继续往后匹配
y++;
z++;
}
else {
//当匹配失败时
z = next[z];//通过next数组找到下一次匹配的字符下标
}
}
return T[z] ? -1 : y - z;//通过z指向的模式串所对应的元素进行判断
//ASCII码值为0,则三目操作符的值为y - z
//ASCII码值不为0,则三目操作符的值为-1
}
3.4 代码测试
由于现在我们是通过手算获取的next数组,所以这次测试我们就以今天的例子进行测试:

可以看到现在是可以很好的实现定位操作的。
四、KMP算法的缺陷
现在我们实现的KMP算法其实并不是最优的算法,它还是会存在缺陷,如下所示:

从上图中可以看到,到第j个字符失配时,我们通过next数组找到了下一次匹配的对象next[j],但是此时next[j]对应的元素与j对应的元素相同,这时的匹配实际上也是无用的匹配过程,因此现在我们实现的KMP算法是可以进一步优化的,具体的优化方案我们将会在下一篇内容中详细介绍,大家记得关注哦!!!
结语
在今天的内容中我们详细介绍了KMP算法的相关内容,通过今天的内容,我们认识到了4个概念:
- 前缀:除了字符串最后一个字符以外的所有头部子串
- 后缀:除了字符串首字符以外的所有尾部子串
- 部分匹配值(Partial Match,PM):字符串的前缀与后缀相等的最长前后缀长度
- next数组:记录匹配失败时下一次匹配的元素下标的整型数组
之后经过KMP算法的探讨,我们得到了以下结论:
KMP算法就是通过next数组规避无用匹配过程的算法;- next数组中的值与失配字符的前一个字符的PM值相等,即: n e x t [ j ] = = P M j − 1 next[j]==PM_{j-1} next[j]==PMj−1
- 第 j j j 个元素失配后的移位匹配过程实际上就是 1 ~ ( j − 1 ) 1~(j-1) 1~(j−1)个匹配成功的字符组成的子串的前后缀的匹配过程;
最后我们还简单介绍了以下今天实现的KMP算法中存在的缺陷。
今天的内容到这里就全部结束了,在下一篇内容中,我们将重点介绍如何通过程序实现模式串的next数组求解,以及如何完善KMP算法,感兴趣的朋友记得关注哦!!!如果大家喜欢博主的创作内容,可以给博主的作品进行点赞、收藏加评论,当然也可以分享给你身边需要的朋友。最后感谢大家的支持,咱们下一篇再见!!!




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-12-蜂鸣器](https://img-blog.csdnimg.cn/direct/72cfe6557d7d46efa1d2f9325911bfbc.png)